The DNA-encoded library (DEL) technology allows preparation of millions of druglike molecules each linked to a unique DNA sequence, which are selected as a mixture for binding affinity against a protein. Since each DNA tag encodes the structure of its associated molecule, high-affinity protein binders can be identified by DNA sequencing, making DEL screening a simpler and affordable hit discovery strategy.
DNA barcode design
The DNA barcode design is an essential component of successful selections; we propose to use a system developed and validated by Andreas Bruenschweiger, which is based on:
- 8mer DNA codon sequences (48 = ~65k unique codes, commercially available in plate format).
- Codes with Hamming distance of 3, i.e. each code differs from each other by at least 3 nucleobases, using an algorithm developed by Brunschweiger.
- 5’-phosporylation of DNA codons by polynucleotide kinases prior to T4 DNA ligation, which gives significantly improved fidelity in our hands. In contrast to commercially available ligation-ready 5’-phosphorylated DNA, the codons can be stored for years.
Library synthesis
To prepare our libraries we initially collected around 650 mono- and bi-functional chemically diverse building blocks that would allow us to utilise them interchangeably among several DELs. The diversity of libraries is driven by the structural diversity of the building blocks used for library synthesis, considering simple 2D similarity (e.g. Tanimoto distance) alongside variations in ionisation, lipophilicity, hydrogen bonding potential and conformational limitations/preferences. To carry out this selection we used KNIME, a data analysis platform, to help us choose building blocks with the purpose of maximising the coverage of chemical space. The building blocks were sourced from in-house chemical stock at The University of Manchester and Newcastle University, from a donation from GlaxoSmithKline and the Enamine's in-stock-catalogue.
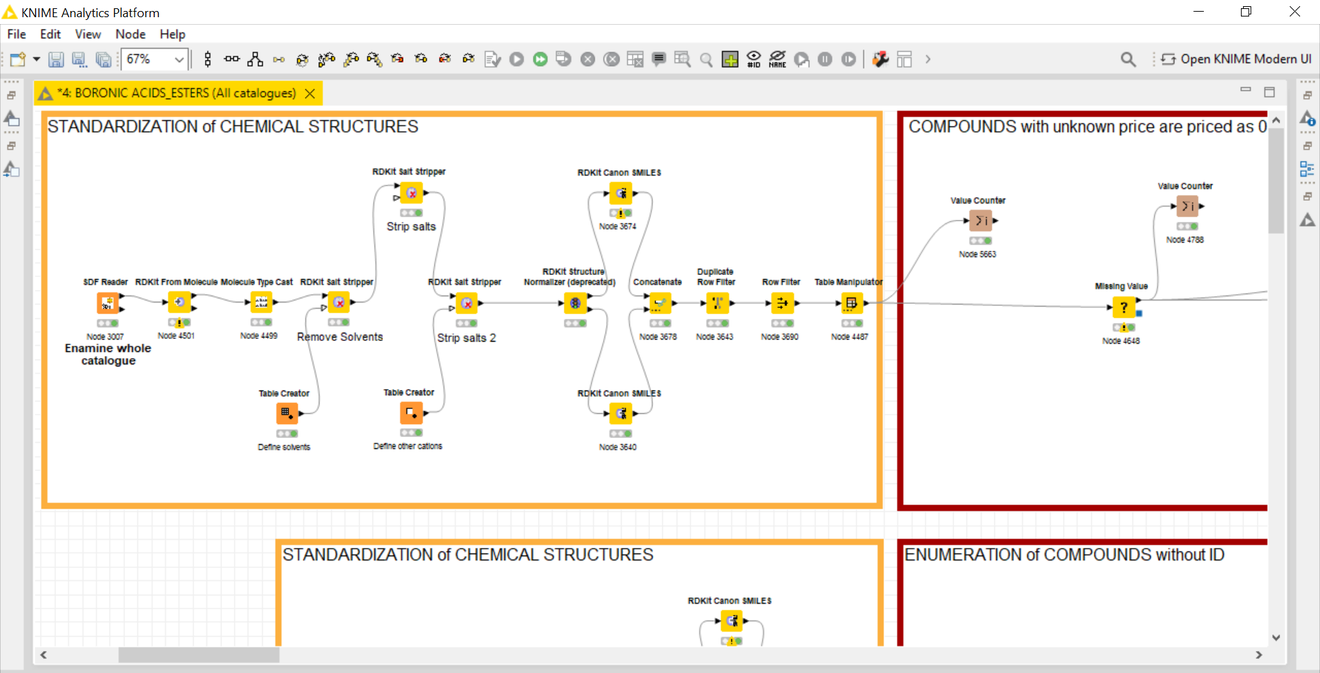
On-DNA chemistry validation allowed us to further curate a collection of building blocks suitable for DEL synthesis. The DNA-encoded libraries were synthesised by a convergent synthetic sequence using either solution phase synthesis. Upon completion, we moved into the next stage: validation of the selection protocols.
Selection process
For this purpose we chose to carry out affinity selections against carbonic anhydrase 9, [....], for which we included in all DELs one building block containing a 4-benzenesulfonamide moiety, a known binding pharmacophore for this target.
Libraries are pooled and then exposed to a surface-immobilised target protein of interest. Subsequent washing steps enrich compounds with highest affinity to the target, and these ‘selected’ compounds isolated following denaturing the protein. DNA sequences are amplified by PCR and quantitated by next-generation sequencing for compound identification (figure A3b). Selected protein-binding compounds are readily resynthesised off-DNA and binding cross-validated in biophysical experiments (SPR, Tm).
Outline of the protocol to be undertaken by the Recipient
1) Protein target(s) supplied by Provider will be immobilised on magnetic beads via e.g. His tag/Zn or biotin tag/avidin.
2) Pooled DNA encoded libraries owned by the recipient exposed to target under a variety of buffer conditions.
3) Non-binding compounds washed under a variety of wash conditions, and binding compounds eluted following e.g. thermal denaturation of target protein. Stages 2-3 may be repeated to increase enrichment of binding.
4) Initial PCR analysis of total DNA in samples from stage 4. Where a suitable amount of DNA is present a 2 step PCR will be conducted to expand hit fragments, step one incorporating barcode sequence to allow sequencing of pooled samples, second to add Illumina adapters.
5) Pooled DNA will be sequenced to give fastq data.
6) Deconvolution of sequencing using algorithm to provide hit sequences and enrichment factors.
7) Cluster, building block and property-based analysis of compounds with significant enrichment from individual selection conditions.
8) The selection may be repeated under optimised buffer/wash conditions if required (i.e. lack of clustering or low enrichment factors)
9) Where suitable hits are identified in stage 7, up to 10 compounds per target will be resynthesised on-DNA using library synthesis conditions (without DNA extension), followed by MS analysis to evaluate compound(s) present in each sample
10) Where suitable hits are identified in stage 7, the Recipient will undertake validation of binding of on-DNA compounds by SPR/BLI (using tag-based immobilisation and/or DNA immobilisation) and/or MST/Tm analysis.
11) Where suitable hits are identified in stage 10, the Recipient will undertake resynthesis of up to 5 hit compounds off-DNA, separation of products if relevant, revalidation by SPR/BLI and/or MST/Tm analysis.
The exact selection protocol undertaken by the recipient may be modified from the above, in consultation with the Provider institution. Progression through the selection protocol will be at the discretion of the Recipient, in consultation with the Provider.
The Provider will receive a report of the exact protocol used and a copy of the data from stages 7, 9, 10 and 11.